

TL;DR: Claude Fable 5 matters less as a benchmark headline and more as an enterprise architecture shift. Anthropic is making a Mythos-class model broadly available, but only behind active safeguards, model fallbacks, and a stricter 30-day retention policy. For engineering leaders, the question is no longer “is the model good?” It is “which workflows will reliably stay on Fable, which will be downgraded to Opus 4.8, and what governance do we need before teams wire this into production?”
That framing is the real story. Anthropic is effectively splitting frontier AI into two products: a generally accessible model with guardrails, and a trusted-access variant with more of the raw capability exposed. If you run software engineering, platform, security, or applied AI teams, that split changes evaluation, rollout, and risk management.
If you want background on why Anthropic has been unusually conservative around this capability tier, start with our breakdown of Claude Mythos Preview. And if your team is already standardizing around Anthropic tooling, this technical guide to the Claude ecosystem is the broader operating manual.
What Anthropic actually launched
Anthropic launched two closely related products:
Claude Fable 5: the general-availability model, with safeguards that divert some sensitive requests away from Fable.
Claude Mythos 5: the same underlying model, but with some safeguards lifted for approved users through a trusted access program.
That distinction is crucial. On paper, these are not separate capability classes so much as separate access policies over the same capability base. Anthropic is saying, in effect: we think the model is powerful enough to be broadly useful, but dangerous enough that broad access requires runtime controls.
Pricing is also notable: $10 per million input tokens and $50 per million output tokens. That is aggressive relative to the level of capability being claimed, and it lowers the barrier for teams that want to push more long-horizon agent workflows into production.
Why this launch is strategically different
Most model launches are framed around benchmark gains. This one is framed around conditional access. That is a sign the model frontier has moved into a new operational regime:
Capabilities are now strong enough that misuse prevention cannot be handled by policy text alone.
Providers are introducing active enforcement systems between the user and the model.
“The model” is becoming a composite service: primary model + classifiers + fallback model + logging + retention policy.
For enterprises, that means model selection can no longer be separated from control-plane design. This is the same governance direction we are seeing elsewhere in enterprise AI, including the rise of platforms that manage agent sprawl and policy centrally, as we discussed in our analysis of Microsoft Agent 365.
How strong is Fable 5?
Anthropic’s position is that Fable 5 is state-of-the-art or near state-of-the-art across software engineering, knowledge work, vision, long-context memory, and some scientific tasks. The biggest practical claim is not just higher scores, but better performance on long, multi-step tasks.
That matters more than headline benchmark deltas. Engineering orgs do not buy frontier models to answer trivia. They buy them to complete migrations, debug systems, review codebases, synthesize dense documentation, and operate with partial autonomy over hours instead of minutes.
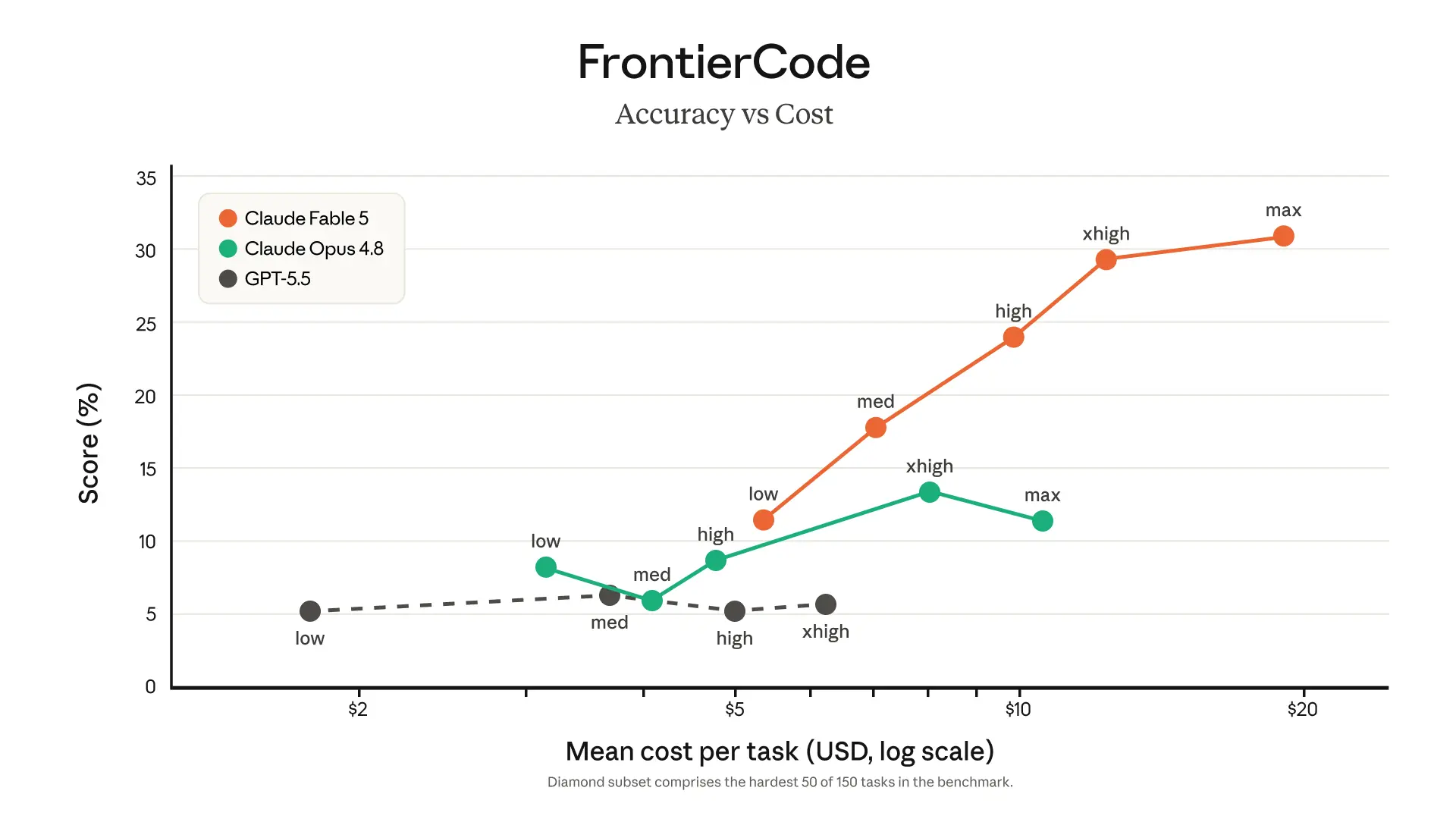
Where engineering leaders should pay attention
Codebase-wide changes: Anthropic cites examples of large migrations compressed from months to days.
Fewer turns: Multiple early users report stronger one-shot or low-turn execution, which improves both cost and workflow reliability.
Token efficiency: Better outcomes at medium effort levels can matter more than “best possible” outcomes at maximum reasoning budgets.
Vision-based engineering: Rebuilding interfaces from screenshots and reading complex figures expands where AI can assist in the SDLC.
Persistent task focus: Better long-context behavior means less babysitting on sprawling tasks.
This fits the broader pattern we have been tracking in how AI is reshaping the SDLC: the biggest gains are not from autocomplete, but from handing agents bounded chunks of real project work.
Fable 5 vs Mythos 5: the practical difference
Dimension | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
Underlying capability | Mythos-class | Same underlying model |
Availability | General access | Trusted access program |
Safeguards | Active classifiers with fallback in covered domains | Some safeguards lifted in approved areas |
Best fit | General software, analytics, enterprise knowledge work | Cyber defense, critical infrastructure, advanced biomedical research |
Risk posture | Conservative by default | Higher-trust, higher-governance access |
Data retention | 30-day retention for Mythos-class traffic | 30-day retention for Mythos-class traffic |
The key point: in most normal sessions, Fable 5 behaves like the fully capable model. But when classifiers detect certain categories of risk, the request is routed to Claude Opus 4.8 instead.
That fallback design is smart product strategy. A hard refusal destroys workflow continuity. A fallback preserves usability while lowering risk. If you need a deeper sense of where Opus 4.8 sits in the stack, read our guide to Claude Opus 4.8 for engineering leaders.
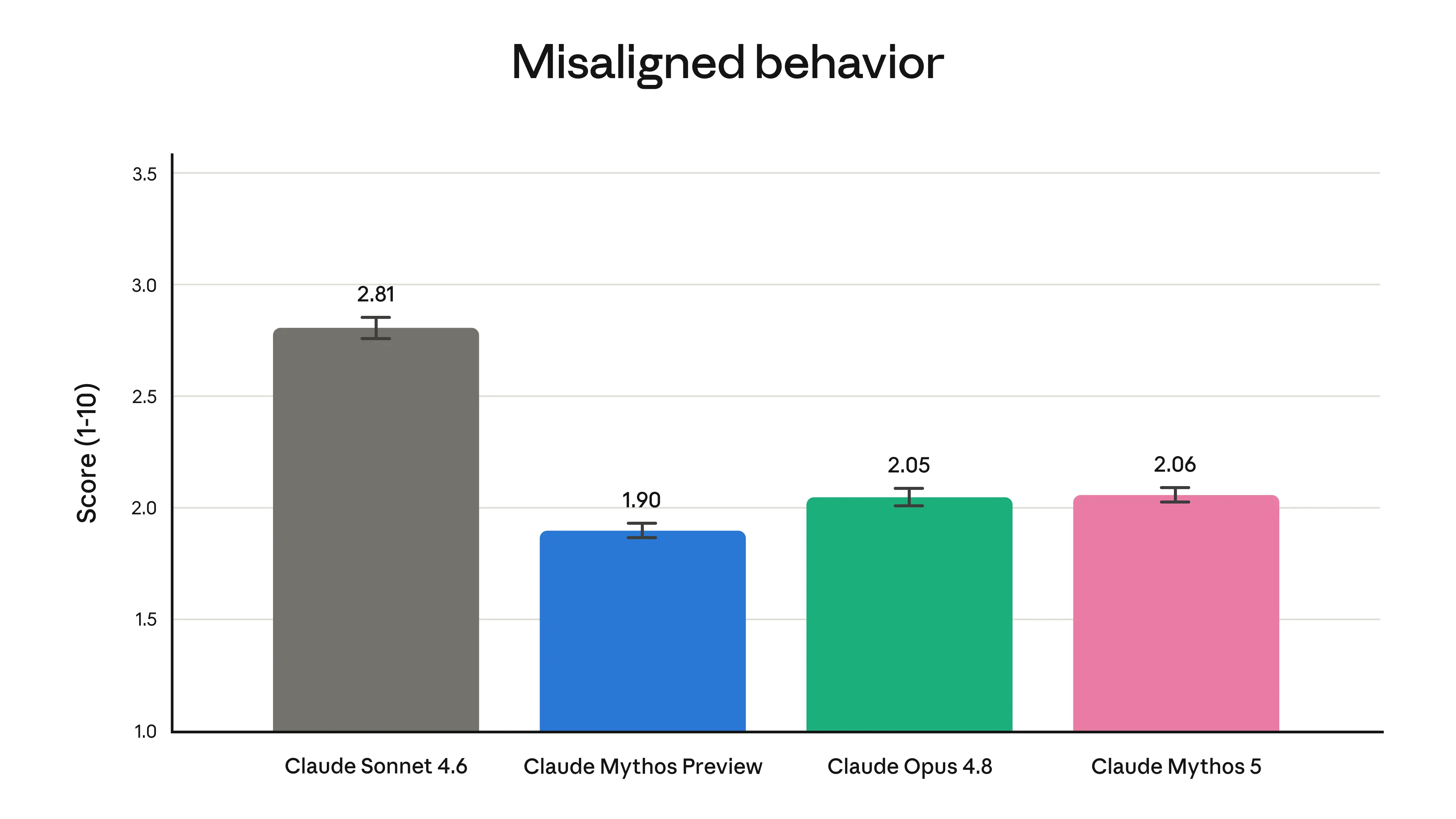
Overall level of misaligned behaviors from our automated alignment assessment. See system card.
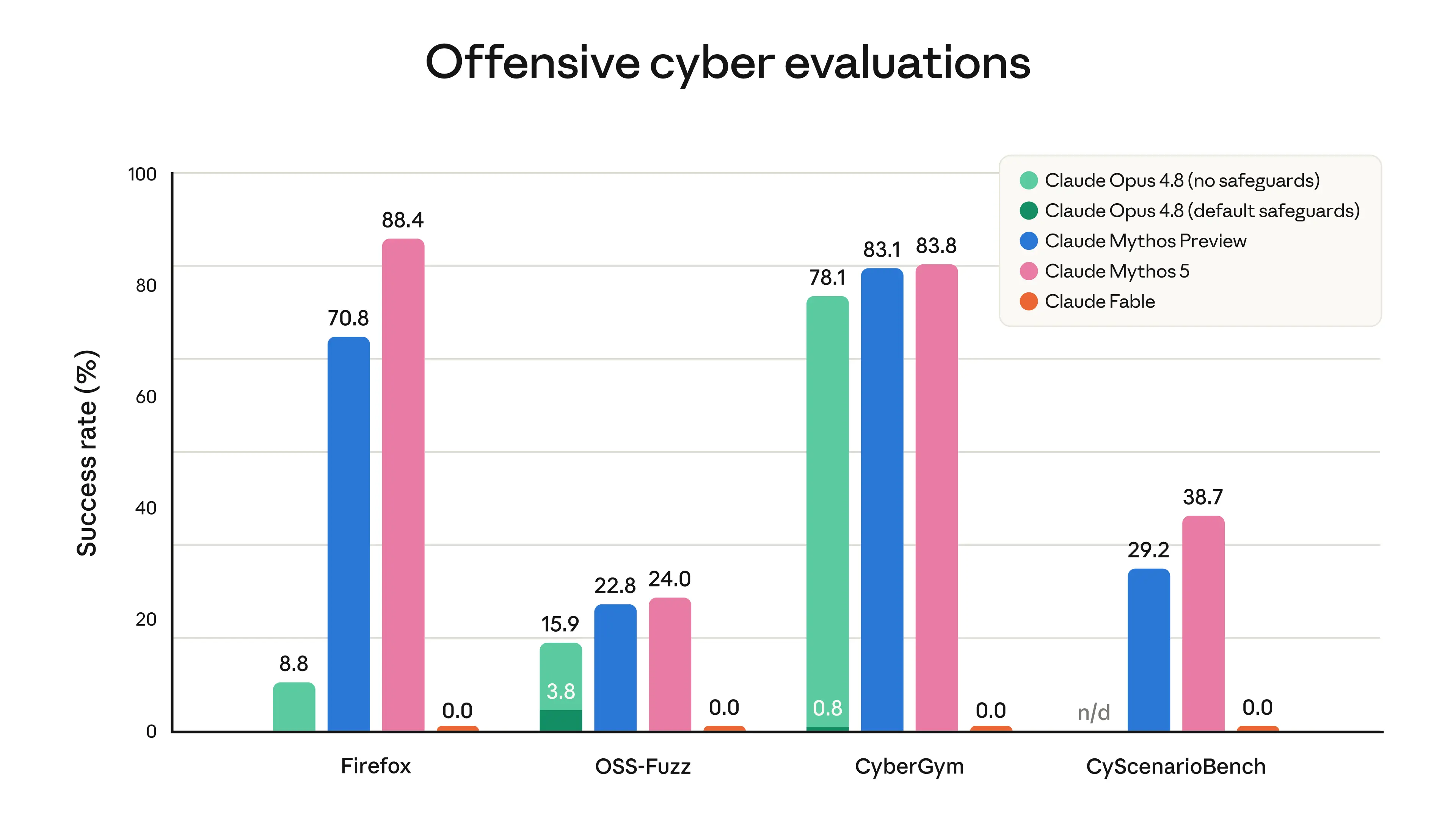
Results of running cyber evaluations,3 with Fable 5 in a mode that blocks responses rather than falling back to Opus 4.8. Evaluations did not involve attempts to evade safeguards.
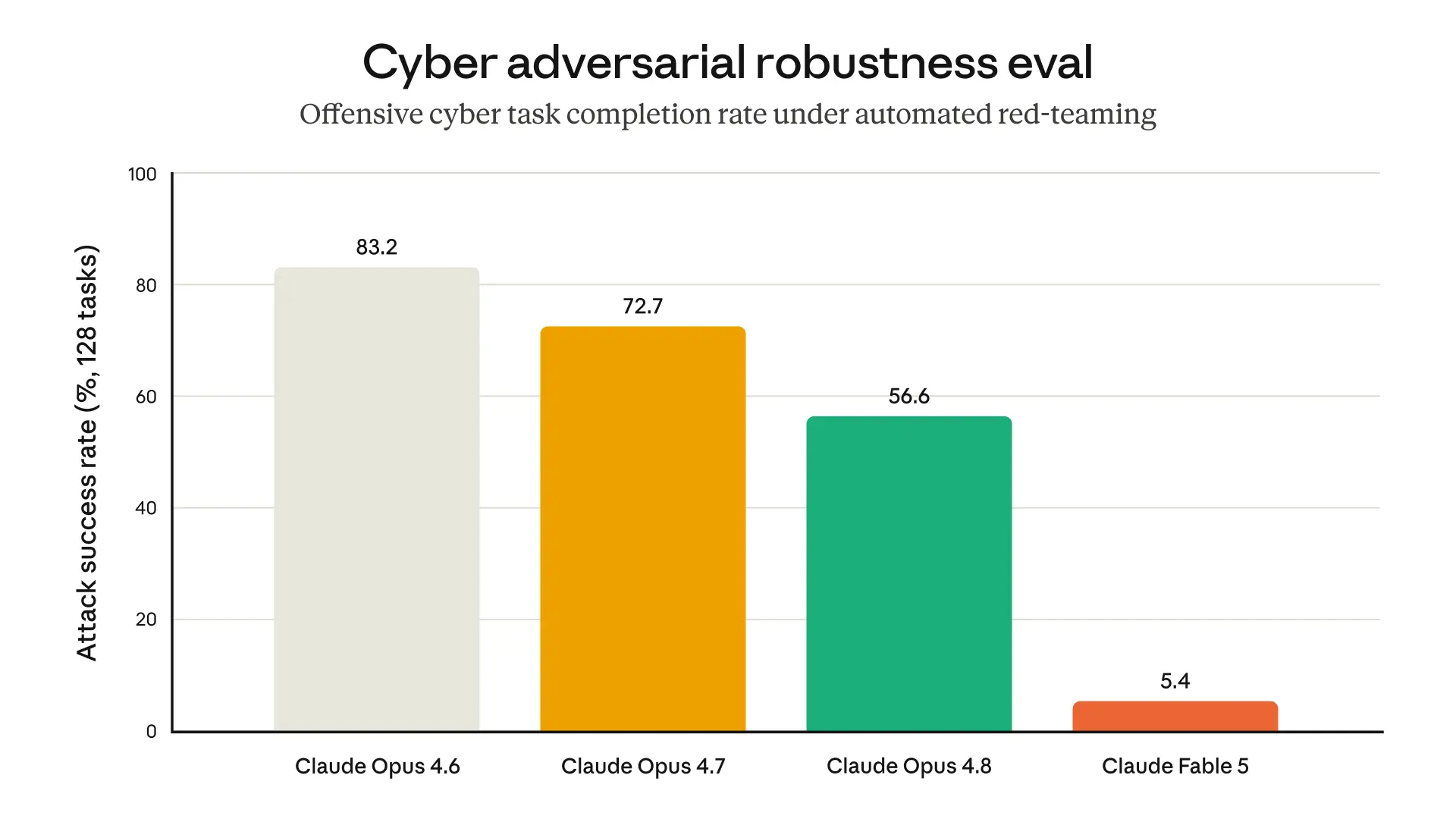
Results of an internal evaluation in which an automated red-teamer tries to use the model to complete a short task related to offensive cybersecurity across 400 turns, restarting and rewinding when blocked. The tasks are mostly simple and not representative of real cyber usage—they are sometimes as simple as encrypting files on a remote server. On more complex and realistic tasks we have not yet seen successful jailbreaks on our production system. Note that Opus 4.6 does not have blocking cyber safeguards.
The safeguard system is the product
Anthropic’s most important innovation here may not be the model at all. It is the safety and access layer around the model.
1. Safety classifiers
Anthropic says Fable 5 uses separate AI systems to detect:
cybersecurity misuse
biology and chemistry misuse
distillation attempts
jailbreak behavior
When triggered, these classifiers cause the response to be handled by Opus 4.8 rather than Fable 5.
Anthropic claims these fallbacks occur in less than 5% of sessions on average, which implies the general user experience remains mostly unaffected. But averages can be misleading. If your business operates in security, infrastructure, biotech, compliance, or reverse engineering, your fallback rate could be materially higher.
2. Cybersecurity controls
This is the most mature and most consequential safeguard area. Anthropic is explicit that Mythos-class models can materially aid offensive cyber operations, including agentic hacking workflows spanning reconnaissance, exploitation, and lateral movement.
For engineering leaders, that creates a weird but important split:
Defensive security teams may have legitimate reasons to want stronger capability exposure.
General engineering teams may hit unexpected fallbacks while doing benign security-adjacent work like debugging auth flows, analyzing malware samples, or reproducing vulnerabilities internally.
If you run AppSec or platform security, assume your evals must test not just model quality, but classifier interference. For many teams, the product question is no longer “can the model do security work?” but “can the model do enough of our security workflow without degrading into fallback behavior?”
3. Biology and chemistry controls
Anthropic appears even more conservative here. It says many biology and chemistry requests currently fall back to Opus 4.8 because dual-use scientific capability has advanced faster than narrow risk filters can safely handle.
That is a strong signal to life sciences teams: Fable 5 may be impressive in research contexts, but broad biomedical deployment will likely remain gated by trusted-access pathways for some time.
4. Distillation controls
This part may get less press, but it matters commercially. Anthropic is using classifiers to detect attempts to extract model behavior at scale for training competing systems. That suggests frontier providers increasingly see API misuse not just as a policy problem, but as an adversarial security problem.
Expect more providers to follow.
What the 30-day retention policy means for enterprises
Anthropic says Mythos-class traffic will require 30-day retention across first- and third-party surfaces, with the data used for safety-related purposes rather than model training. That will be acceptable for some orgs and a blocker for others.
Who should pause before rollout
Teams handling highly sensitive customer data
Regulated industries with strict retention constraints
Organizations that standardized on zero-retention assumptions for AI usage
Internal legal or security teams expecting stronger isolation guarantees
Even if Anthropic’s controls are sound, this is still an architectural and procurement issue. Your governance team needs a clear answer to:
What data can reach Fable or Mythos-class endpoints?
What must be redacted or abstracted first?
Which workloads should stay on lower-tier models or private patterns like retrieval pipelines?
For many enterprise deployments, this reinforces the value of RAG-based architectures that limit direct exposure of raw proprietary content while preserving high-answer quality.
Where Fable 5 is likely to deliver real ROI
Not every strong model creates economic value. The teams that benefit first are the ones with high-cost, high-latency knowledge workflows that can be bounded, verified, and measured.
Best early use cases
Large-scale refactors and migrations: framework upgrades, API changes, test rewrites, dependency modernization
Engineering investigation work: incident analysis, root-cause synthesis, architecture mapping
Complex document reasoning: contracts, specs, financial analyses, design docs
Vision-heavy workflows: extracting values from charts, converting UI screenshots into working prototypes
Long-running task orchestration: overnight agent workflows with persistent notes and iterative verification
These are also the workflows most likely to benefit from structured harnesses rather than raw prompting. We have seen this repeatedly in production: the best outcomes come from wrapping frontier models in repeatable task scaffolding, tool access, state handling, and verification loops. That is why patterns like dynamic workflows in Claude Code matter so much.
Where teams will get disappointed
Every frontier model launch creates a second wave of disappointment from teams that expected “senior engineer in a box.” Fable 5 will be no different.
Common failure modes to expect
Workflow fragility at the edges: great on the happy path, less reliable when a task requires messy environmental adaptation.
Safety-trigger confusion: teams may interpret fallback behavior as random quality swings.
Over-trust from strong first impressions: better reasoning can hide subtle but expensive mistakes.
Context overload: long context is helpful, but dumping everything into the prompt is still bad systems design.
No evaluation discipline: organizations buy the model and skip the hard work of defining success metrics.
This is why rollout should be eval-first, not hype-first. Anthropic’s own framing, interestingly, supports that. The product is designed around measured access and bounded risk, not unconstrained autonomy.
A decision framework for engineering leaders
If you are deciding whether to adopt Fable 5 now, use five questions.
1. Are your target workflows mostly outside guarded domains?
If your immediate value is in software engineering, product ops, analytics, and general knowledge work, Fable 5 is more attractive. If your workflows are deeply cyber or wet-lab adjacent, expect more friction.
2. Can you verify outputs cheaply?
The best AI economics happen when a model can compress expensive human work but humans can still validate the result quickly. Code review, test suites, schema validation, and deterministic checks all help.
3. Is 30-day retention acceptable?
If not, stop there. Do not force a rollout that violates your governance baseline.
4. Do you have a control plane for agents?
As models get more autonomous, unmanaged usage becomes an operations problem. You need visibility into who is using what model, on which data, with what tools, and at what cost.
5. Do you know when to use a cheaper model?
One of the most common deployment mistakes is sending every task to the most capable model. In practice, orgs need tiered routing by risk, latency, and complexity. Use frontier models for high-value long-horizon tasks, not every support macro and CRUD scaffold.
What Anthropic’s launch tells us about the future of AI platforms
This launch points to three broader trends.
Models will increasingly ship as governed systems, not raw endpoints
Expect more classifier layers, fallback behaviors, reputation systems, and trusted-access tiers. The age of “single API, same capability for everyone” is ending at the frontier.
Capability and governance will become inseparable in procurement
Enterprise buyers will compare not only benchmark quality but retention, auditability, abuse monitoring, fallback logic, and domain-specific controls.
Agent architecture will matter more than model deltas
As models get stronger, the durable advantage shifts toward orchestration, memory, retrieval, tools, and verification. In other words: how you build around the model matters more than whether one benchmark moved by 3 points.
That is also why memory design is becoming a board-level practical issue for serious AI deployments. If your agents lose state or cannot maintain structured working memory, you will not capture the full value of long-horizon models. We covered this in our guide to the AI agent memory problem.
LAXIMA’s take: Fable 5 is a release about operating model, not just intelligence
The simplistic read is: Anthropic launched a very strong model and a stronger restricted model. The better read is: Anthropic is prototyping the default governance pattern for frontier AI.
That pattern looks like this:
a highly capable general model
active runtime classifiers
graceful fallback to a safer model
tiered access for trusted users
higher-retention logging for abuse detection
We expect this pattern to spread. Not because vendors love friction, but because frontier capability now creates enough upside and enough misuse risk that pure open access is becoming harder to justify.
For engineering leaders, that means your AI roadmap should evolve from model adoption to capability governance. The organizations that win will not just have the smartest models. They will have the cleanest routing logic, the best evals, the strongest data boundaries, and the clearest human-review protocols.
FAQ
Is Claude Fable 5 the same model as Claude Mythos 5?
Anthropic says they are the same underlying model, but Fable 5 runs with safeguards that can route some requests to Claude Opus 4.8 instead. Mythos 5 offers broader capability exposure for trusted users.
How often do Fable 5 safeguards trigger?
Anthropic says fallbacks occur in less than 5% of sessions on average. But your actual rate may be higher if your work frequently touches cyber, biology, chemistry, or behavior that resembles distillation or jailbreak attempts.
What is the biggest enterprise concern with Fable 5?
For many teams, it is the 30-day data retention requirement on Mythos-class traffic. For others, it is workflow unpredictability when safeguards trigger during legitimate work.
Should engineering teams use Fable 5 for coding?
Yes, likely for selected workflows. It appears strongest where tasks are long-horizon, high-context, and economically meaningful: migrations, refactors, codebase analysis, and multi-step implementation work. But teams still need tests, review gates, and evals.
What should leaders do before rollout?
1. Define 5-10 representative workflows 2. Measure quality, speed, and total cost per completed task 3. Track fallback frequency in sensitive domains 4. Review retention and privacy constraints 5. Route low-value tasks to cheaper models 6. Set human approval gates for high-impact actions
Bottom line
Claude Fable 5 is a meaningful capability release, but the bigger lesson is architectural. Frontier AI is no longer arriving as a naked model. It is arriving as a governed service stack.
If you are an engineering leader, your job is not just to evaluate how smart Fable 5 is. Your job is to determine whether its safeguards, retention model, fallback behavior, and cost profile fit the workflows you actually need to run. Teams that treat this as a systems decision, not a demo decision, will get the upside without inheriting unnecessary risk.


